1. 建立数据集
**from**`` collections ``**import**`` OrderedDict ``**import**`` pandas ``**as**`` pd ``**import**`` numpy ``**as**`` np examDict``**=**``{ '学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,2.50, 2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50], '通过考试':[0,0,0,0,0,0,1,0,1,0,1,0,1,0,1,1,1,1,1,1] } examOrderDict``**=**``OrderedDict(examDict) examDf``**=**``pd``**.**``DataFrame(examOrderDict) examDf``**.**``head()
2.提取特征和标签
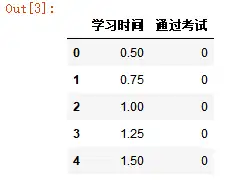
3.绘制散点图
exam_X``**=**``examDf``**.**``loc[:,'学习时间'] exam_y``**=**``examDf``**.**``loc[:,'通过考试'] ``**import**`` matplotlib.pyplot ``**as**`` plt plt``**.**``scatter(exam_X,exam_y,color``**=**``'b',label``**=**``'exam data') plt``**.**``xlabel('Hours') plt``**.**``ylabel('Pass') plt``**.**``show()

4.建立训练数据集和测试数据集
`fromsklearn.cross_validationimport train_test_split X_train,X_test,y_train,y_test=train_test_split(exam_X,exam_y,train_size=.8) print('原始数据特征:',exam_X.shape) print('训练数据特征:',X_train.shape) print('测试数据特征:',X_test.shape) print('原始数据标签:',exam_y.shape) print('训练数据标签:',y_train.shape) print('测试数据标签:',y_test.“shape)
原始数据特征: (20,)
训练数据特征: (16,)
测试数据特征: (4,)
原始数据标签: (20,)
训练数据标签: (16,)
测试数据标签: (4,)
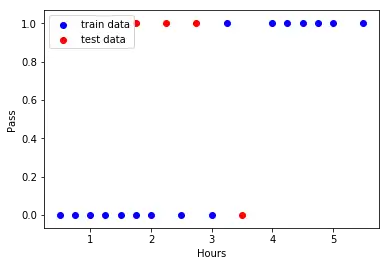
**import** matplotlib.pyplot **as** plt
plt**.**scatter(X_train,y_train,color**=**’blue’,label**=**’train data’)
plt**.**scatter(X_test,y_test,color**=**’red’,label**=**’test data’)
plt**.**legend(loc**=**2)
plt**.**xlabel(‘Hours’)
plt**.**ylabel(‘Pass’)
plt**.**show()`
5.训练模型(使用训练数据)
6.模型评估(使用测试数据)
X_train``**=**``X_train``**.**``values``**.**``reshape(``**-**``1,1) X_test``**=**``X_test``**.**``values``**.**``reshape(``**-**``1,1) ``**from**`` sklearn.linear_model ``**import**`` LogisticRegression model``**=**``LogisticRegression() model``**.**``fit(X_train,y_train) LogisticRegression(C``**=**``1.0, class_weight``**=**``None, dual``**=**``False, fit_intercept``**=**``True, intercept_scaling``**=**``1, max_iter``**=**``100, multi_class``**=**``'ovr', n_jobs``**=**``1, penalty``**=**``'l2', random_state``**=**``None, solver``**=**``'liblinear', tol``**=**``0.0001, verbose``**=**``0, warm_start``**=**``False) model``**.**``score(X_test,y_test) 0.25 model``**.**``predict_proba(3) array([[ 0.41834279, 0.58165721]]) pred``**=**``model``**.**``predict([[3]]) ``**print**``(pred) [1] a``**=**``model``**.**``intercept_ b``**=**``model``**.**``coef_ x``**=**``3 z``**=**``a``**+**``b``*****``x y_pred``**=**``1``**/**``(1``**+**``np``**.**``exp(``**-**``z)) ``**print**``('预测的概率值:',y_pred) 预测的概率值: [[ 0.58165721]]