上篇文章解决了关键词库数据展示的部分,完成了从Tableau本地客户端,到云Saas数跨境BI的迁移。收到了很多的读者的反馈说,他们已经成功解决数据看板的问题,节省了很多时间。
本着同样的逻辑,我们来解决Python清洗的部分,完成从本地端到云端的迁移。
今天要使用的工具是字节跳动出品的豆包MarsCode。这是一个可以运行代码的云IDE软件,不需要本地配置环境,直接在云端执行。
创建项目
1.首先注册MarsCode,由于是大厂出品,可靠性和安全性上不用担心。
注册链接:https://www.marscode.cn/events/s/iSxwCk2J
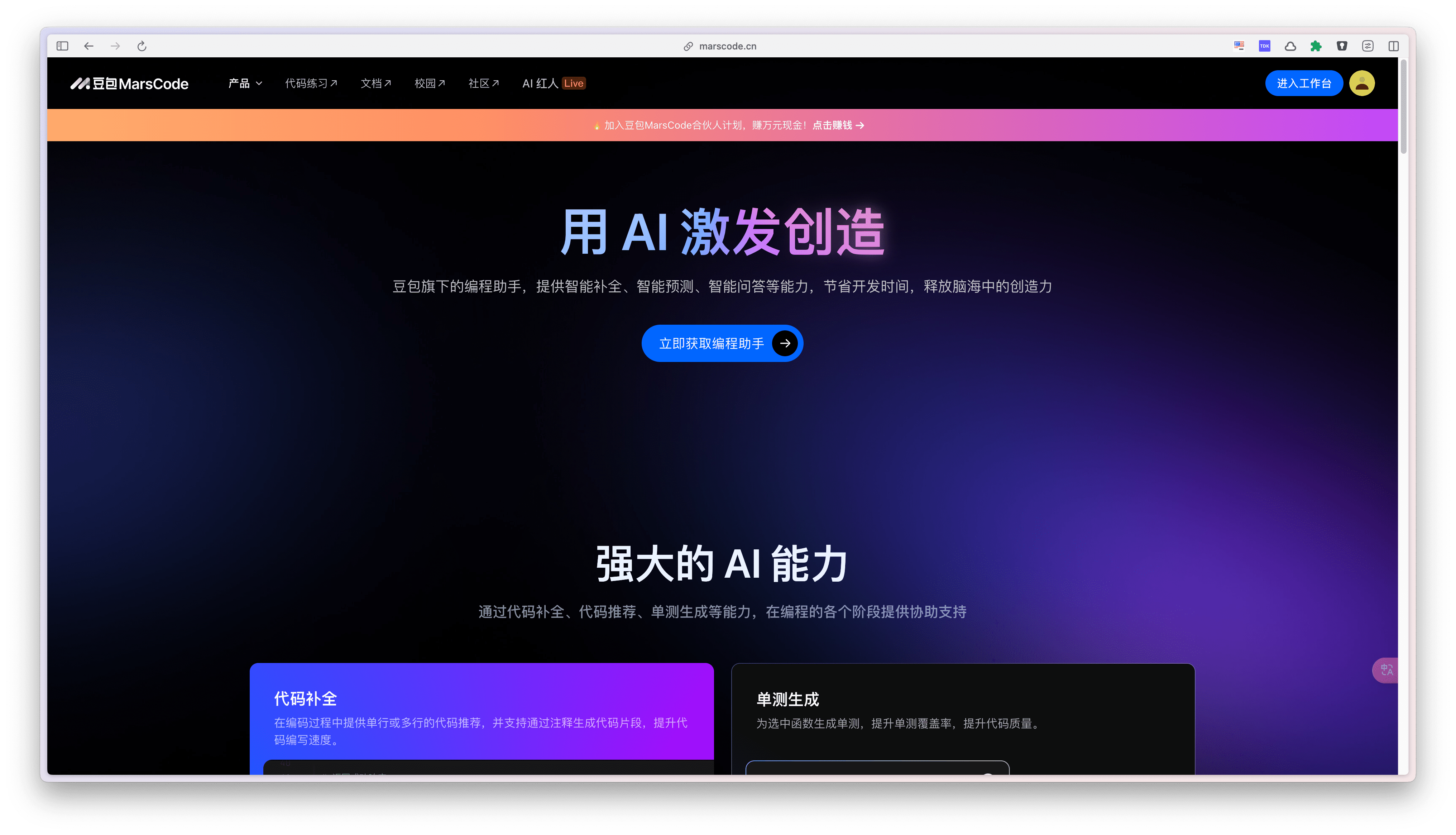
2.进入工作台,选择MarsCode IDE。
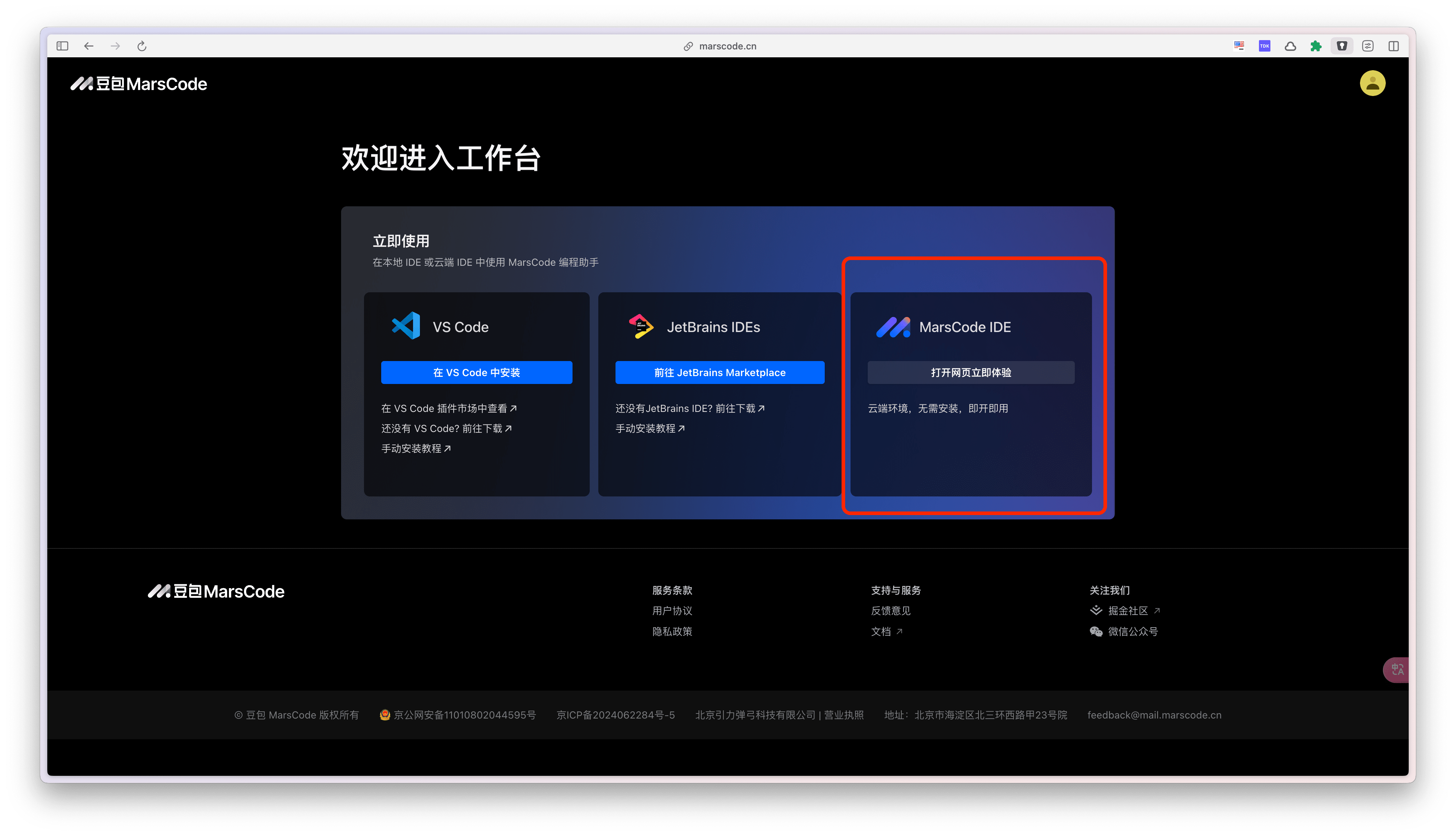
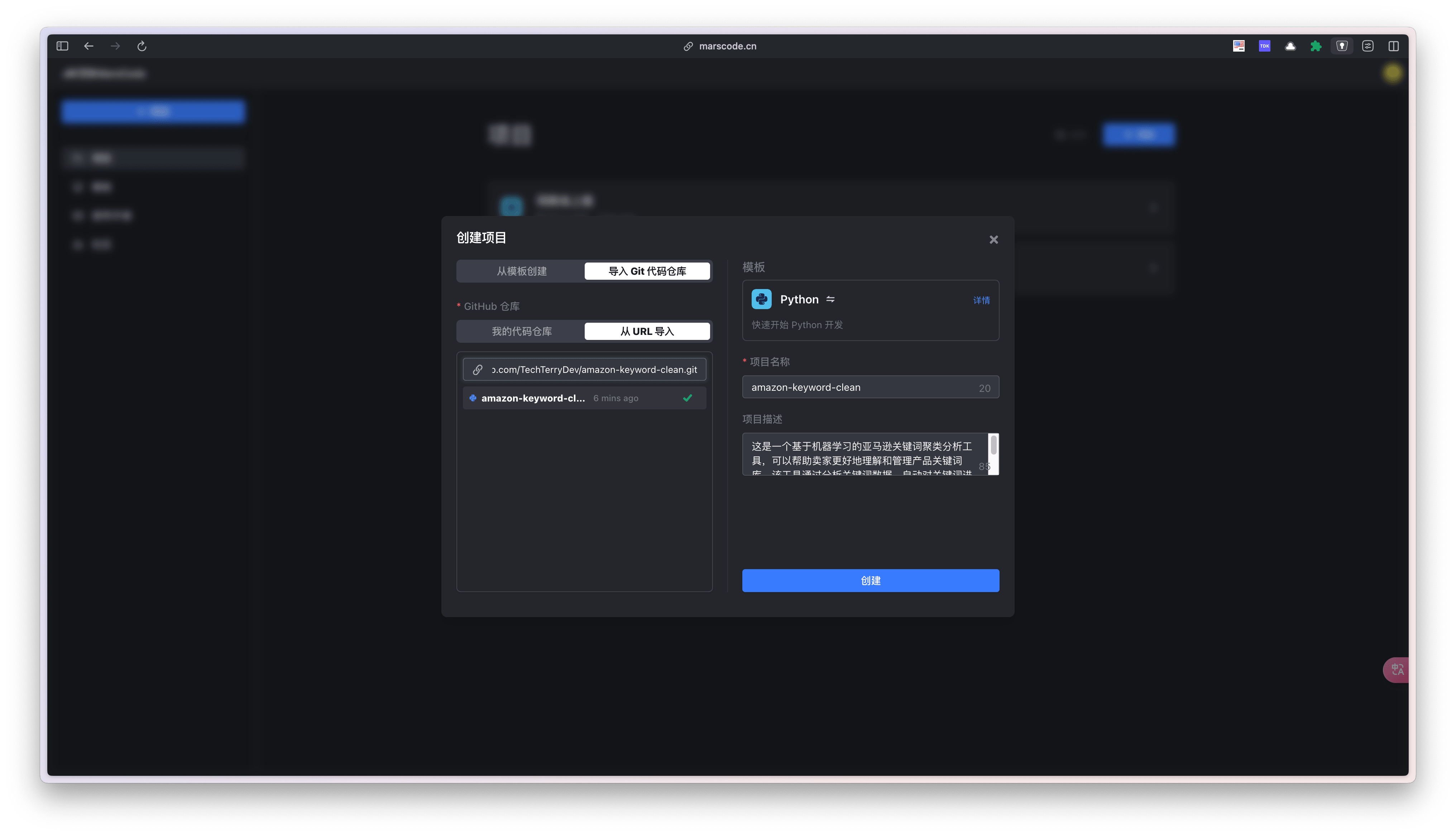
3.新建项目,选择导入git代码仓库,输入我已经上传到github上的项目链接。
https://github.com/TechTerryDev/amazon-keyword-clean.git
执行代码
1.创建好项目之后,在控制台中,复制这行命令安装依赖。
pip install -r requirements.txt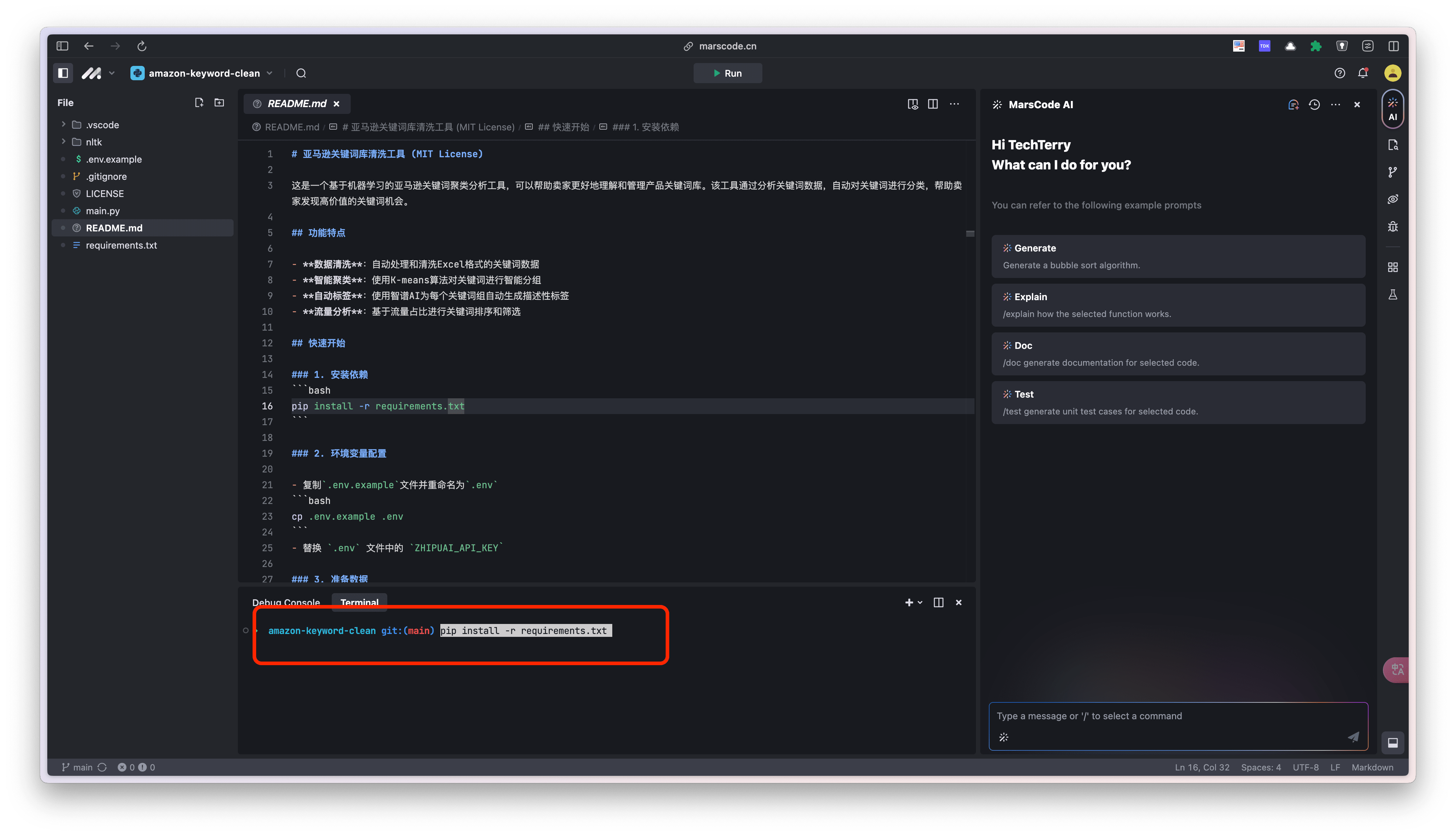
2.复制命令,创建环境变量。
cp .env.example .env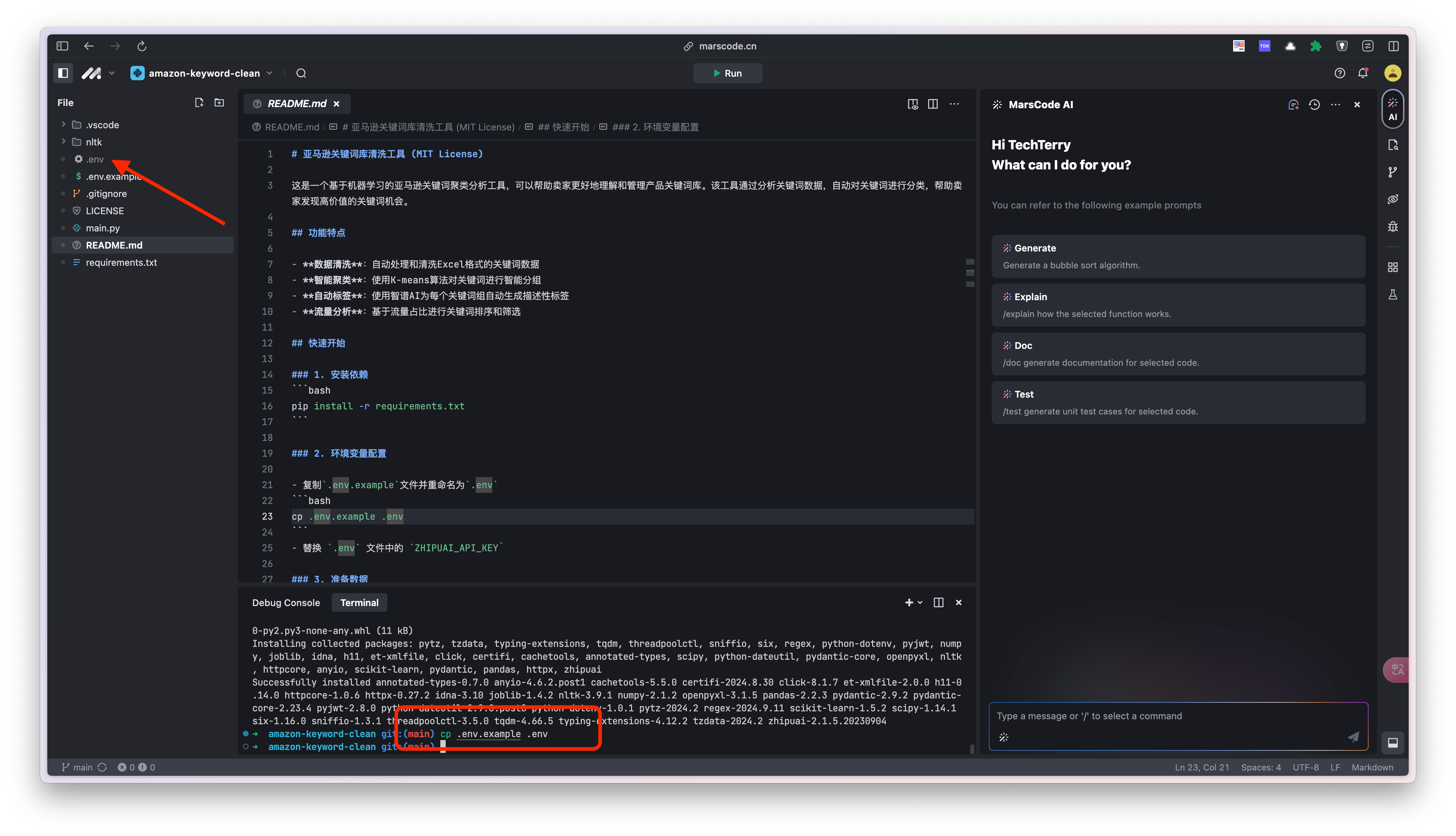
3.把 .env 文件中的 ZHIPUAI_API_KEY 替换成自己的key。
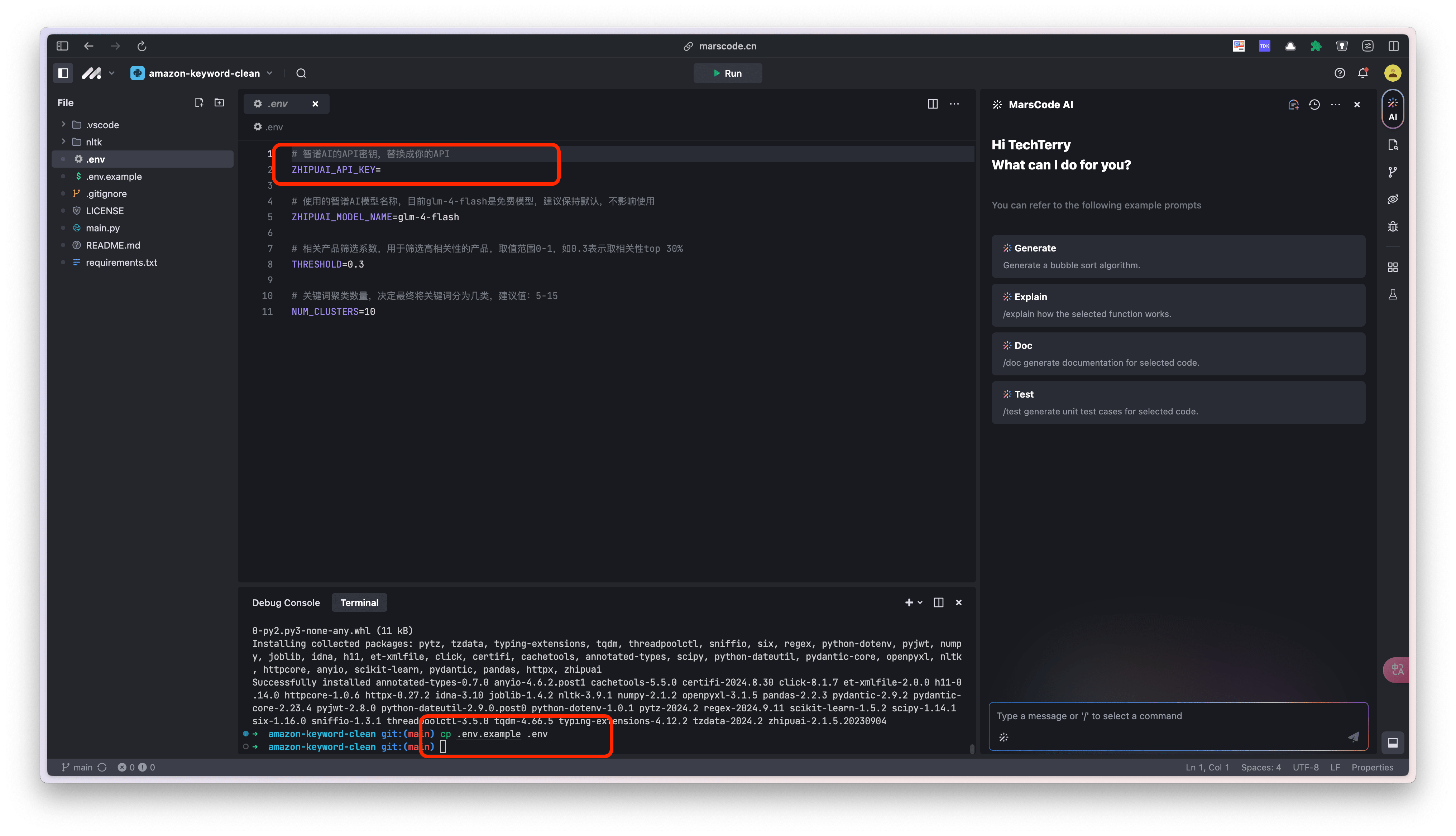
4.把下载好的表格,重命名为 data.xlsx 并上传项目根目录。点击界面顶部的 “Run” 按钮,执行代码。完成后,下载 output.csv 文件。
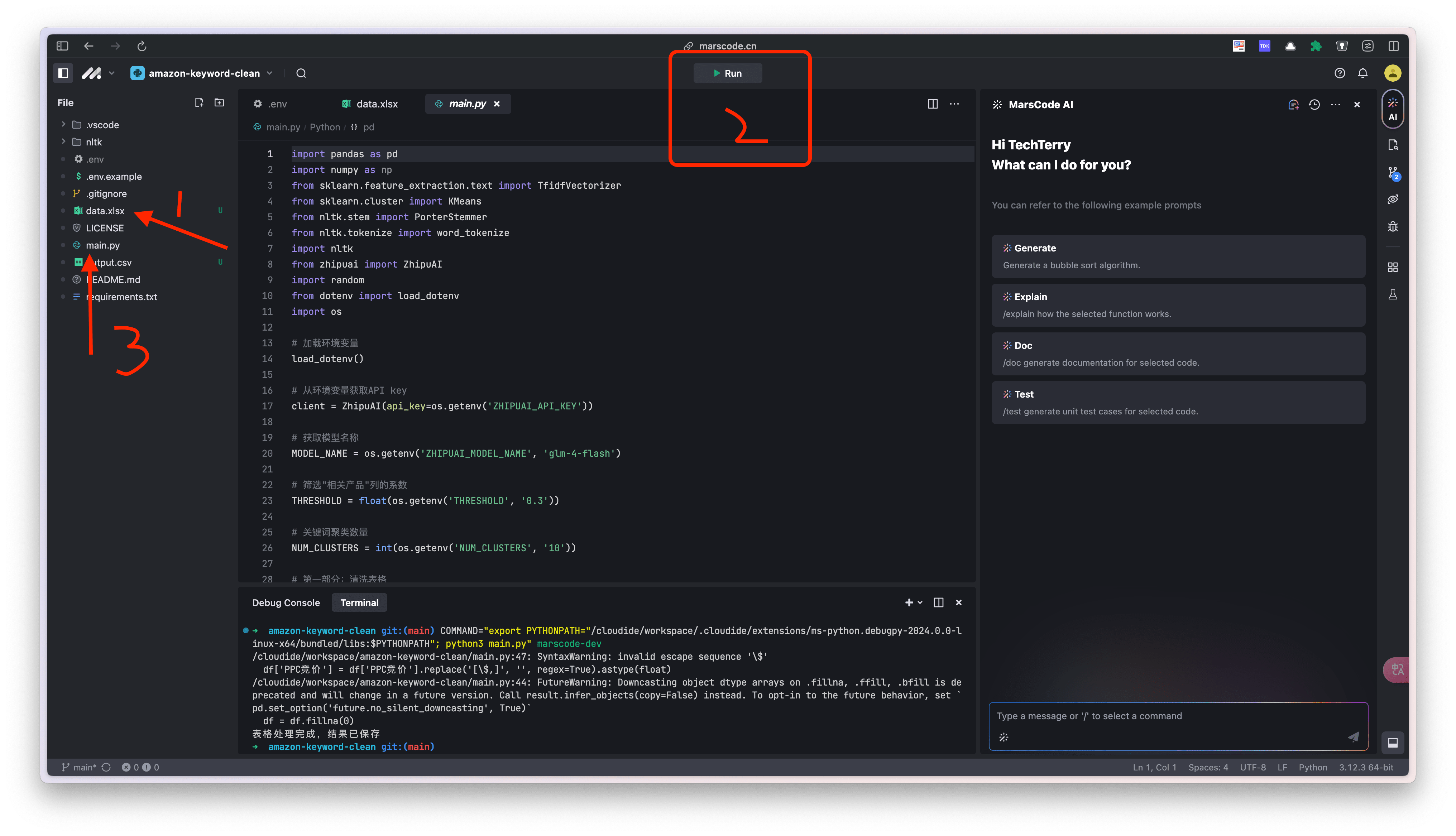
到这里,教程就结束了。整个过程极其优雅,再也不用担心本地配置环境的问题。
修改内容
1.首先解决nltk词库报错的问题,我把需要的文件直接放到项目当中,不需要联网调用。
2.添加了环境变量,可以方便的更换api key、智谱模型、筛选系数和聚类数量。智谱模型换成了免费版的GLM-4-Flash。由于我们使用AI分类的需求比较简单,免费的模型足以胜任。
3.代码托管到了github,后续会直接在上面更新,项目链接地址不变。
总结
到目前为止,关键词库三件套已经形成闭环了。首先找到热卖竞品ASIN,通过卖家精灵导出扩展词,用python清洗表格,用AI给关键词分类,最后在数跨境BI中,生成可视化效果。
第一部分-方法论
https://www.amzalysis.com/article/amazon-keyword-library
https://www.amzalysis.com/article/amazon-sales-breakthrough
第二部分-Python清洗(本篇)
https://www.amzalysis.com/article/keyword-library-python
第三部分-数据分析
https://www.amzalysis.com/article/keyword-library-upgrade
整个过程,本着运营的逻辑,加上个人的思考,借助AI工具,结合读者的反馈,完成从本地到云端的迁移。
即使有了这么多丰富的工具,我也会经常提醒自己,产品和需求才是第一。在AI逐渐成型的今天,工具的价值在于更好的辅助运营,我们可以将更多精力放在提升产品质量和用户体验上,这才是运营工作的核心所在。