最近一周没有更新内容,是因为想在之前第一版的亚马逊listing机器人上面再做升级,结果一发不可收拾。还记得我之前做的基础版的写listing的bot吗?现在来看,真的是太简陋了,虽然引用了知识库,知道给大模型喂语料,但是连基础工作流都没有,跟不用说自定义插件了。所以实现的效果也比较随机,不太能够稳定的运用到生产环境。
https://www.amzalysis.com/article/coze-amazon-listing
其实我不太喜欢标题党,但是我觉得升级后的Agent还是挺强的。强在逻辑和功能上,强在把业务的理解和技术实现相结合。在可实现的范围内,不断的试错,摸索Agent的边界。Coze可以当作一个快速实现MVP的工具,如果有更庞大复杂的需求,可以用其他工具深入实现。目前,这一版的listing写作agent有三个大功能:
- 用户上传关键词表,给出关键词分类
- 通过关键词分类,做出思维导图
- 根据关键词库,和用户给出的产品特点,写出listing
实际效果
我用之前广告分析的投影仪作为例子,先来看下实际的效果。
体验地址:https://www.coze.cn/s/iMD8NbCt/
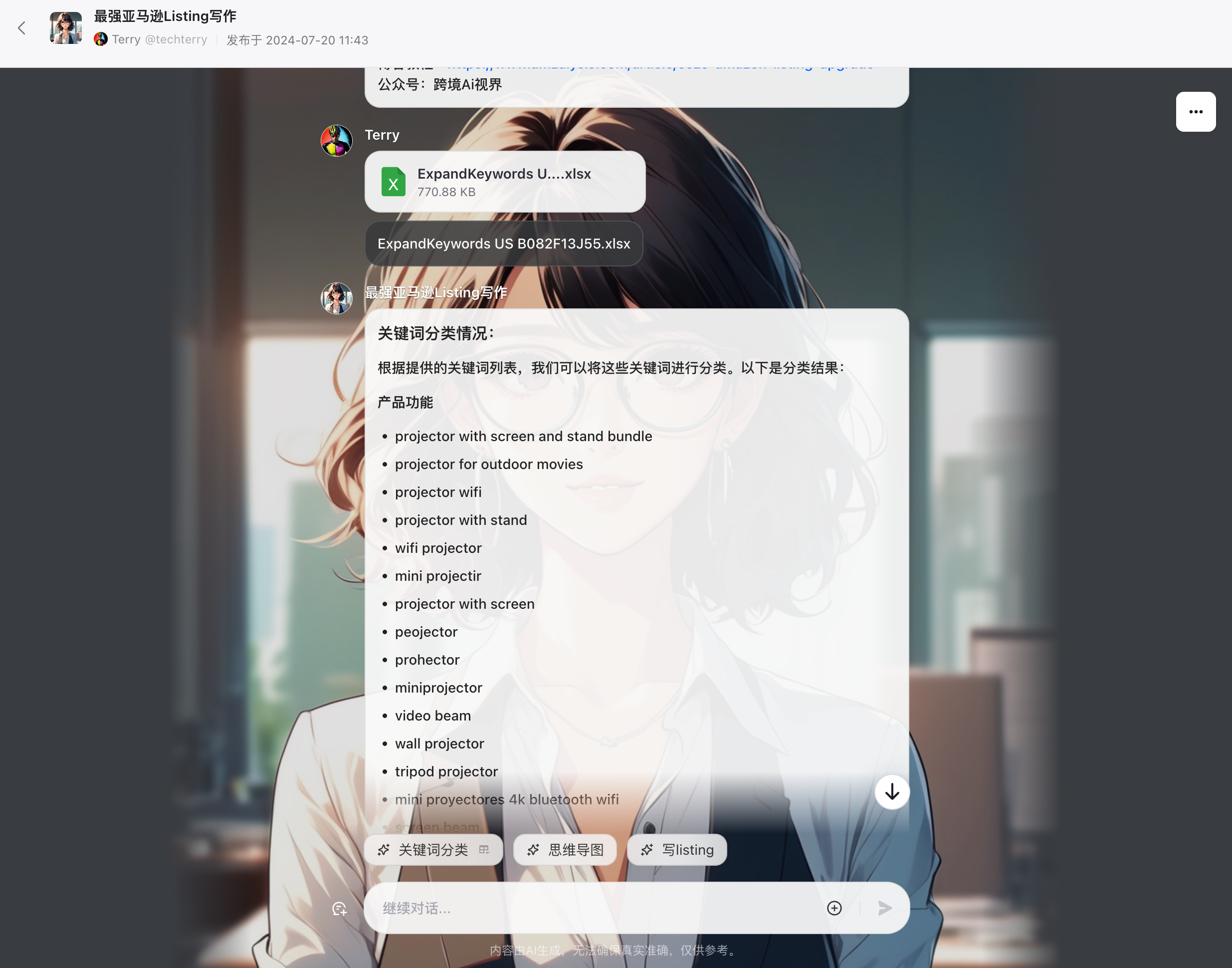
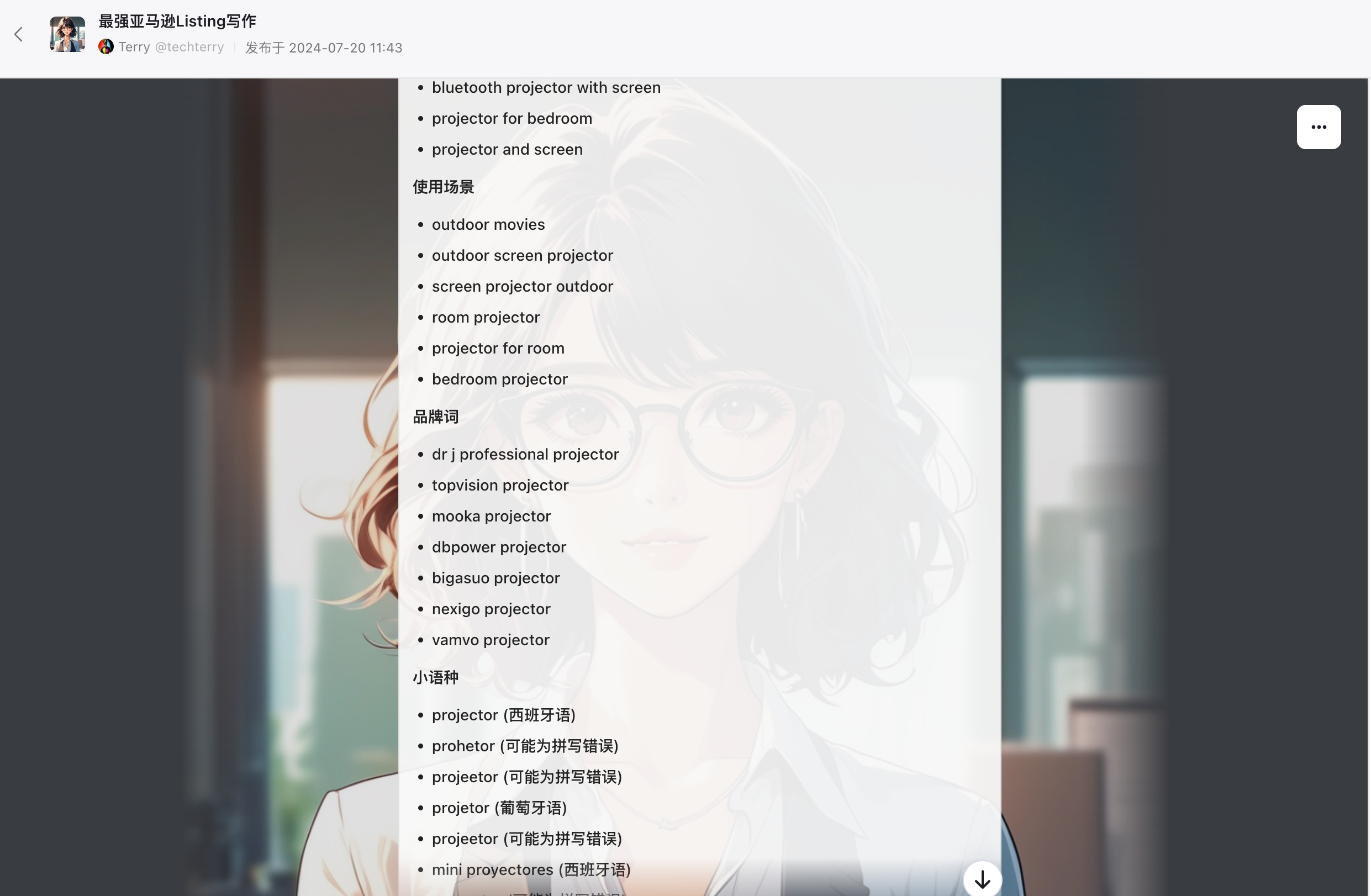
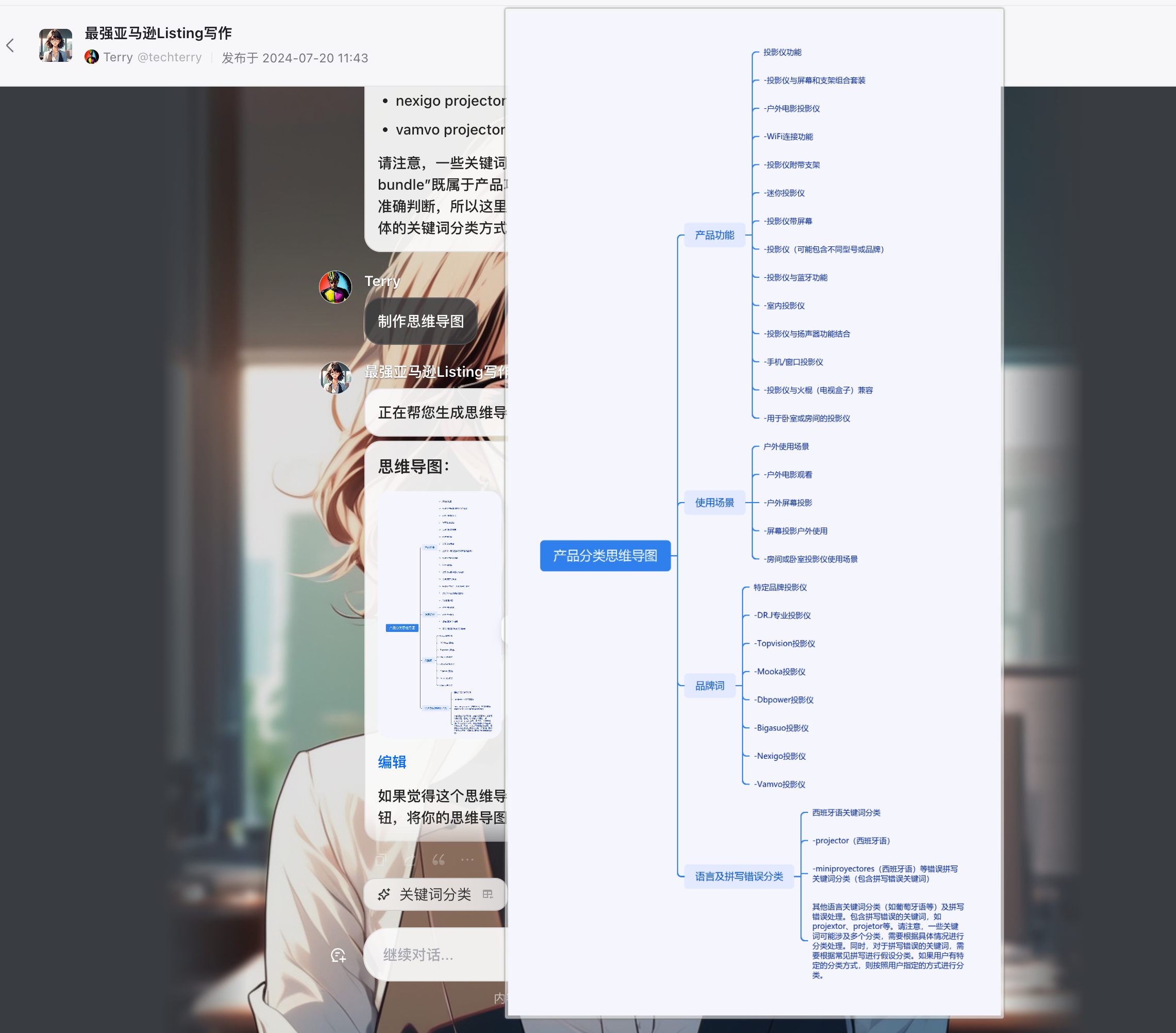
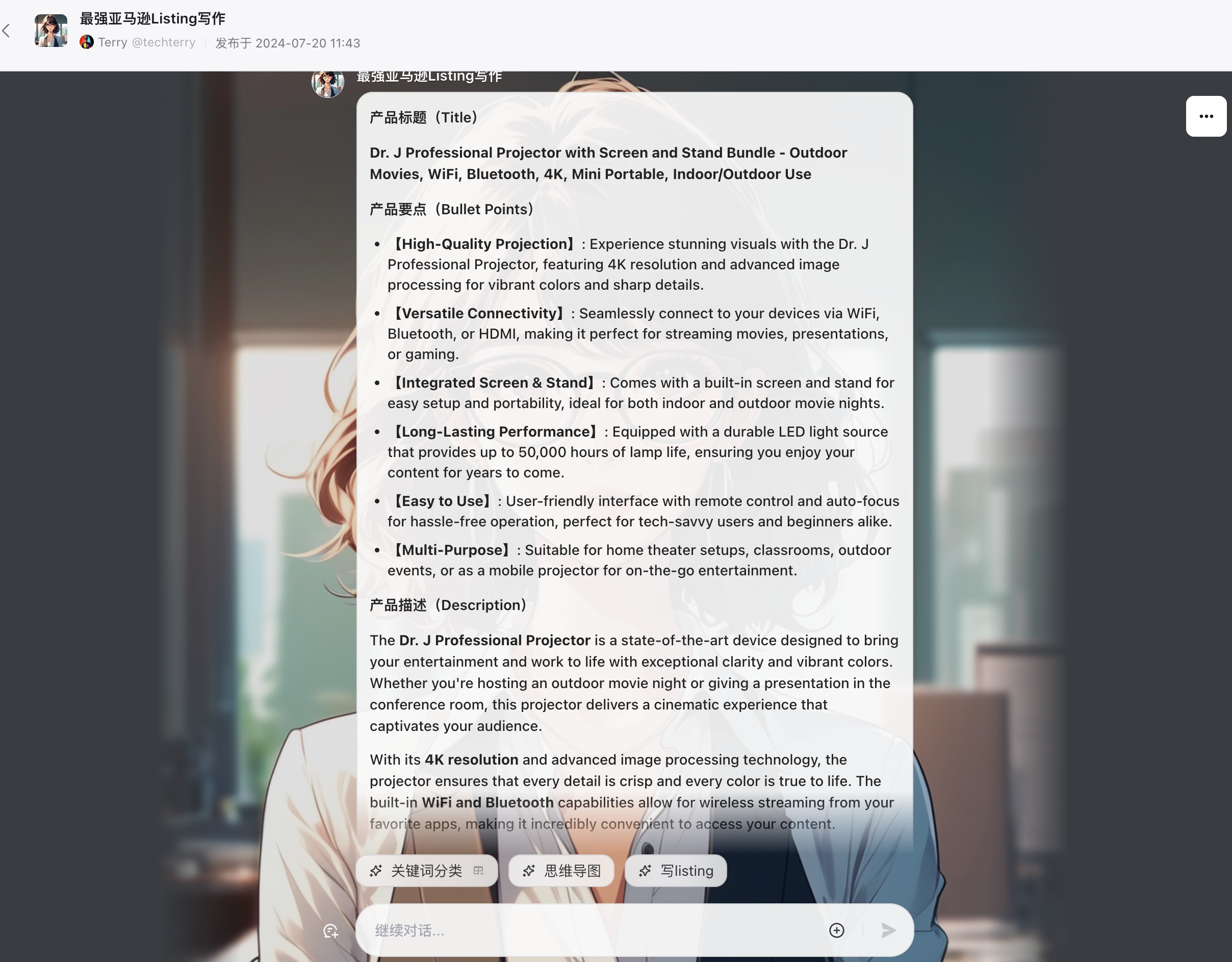
使用说明
由于我在做插件的时候,把数据处理方式写死了,所以需要按我的方法导出关键词表。不过按这个方法基本也可以获取80%的关键词了。
- **找竞品:**找出小类best seller前20的同类产品,如果没有固定的的小类目,也可以通过关键词搜索,最多收集20个销量好的ASIN。
- **反查:**把收集的ASIN放到卖家精灵后台-关键词优化-拓展流量词选项反查相关词。
- **导出表格:**这里我选取的是之前分析过的投影仪类目,20个ASIN导出了3000多个关键词,做词库是够用了吧。
- **Coze:**上传表格到coze机器人,先进行关键词分类,再做思维导图(非必选),最后写出listing。
Coze Bot 制作过程
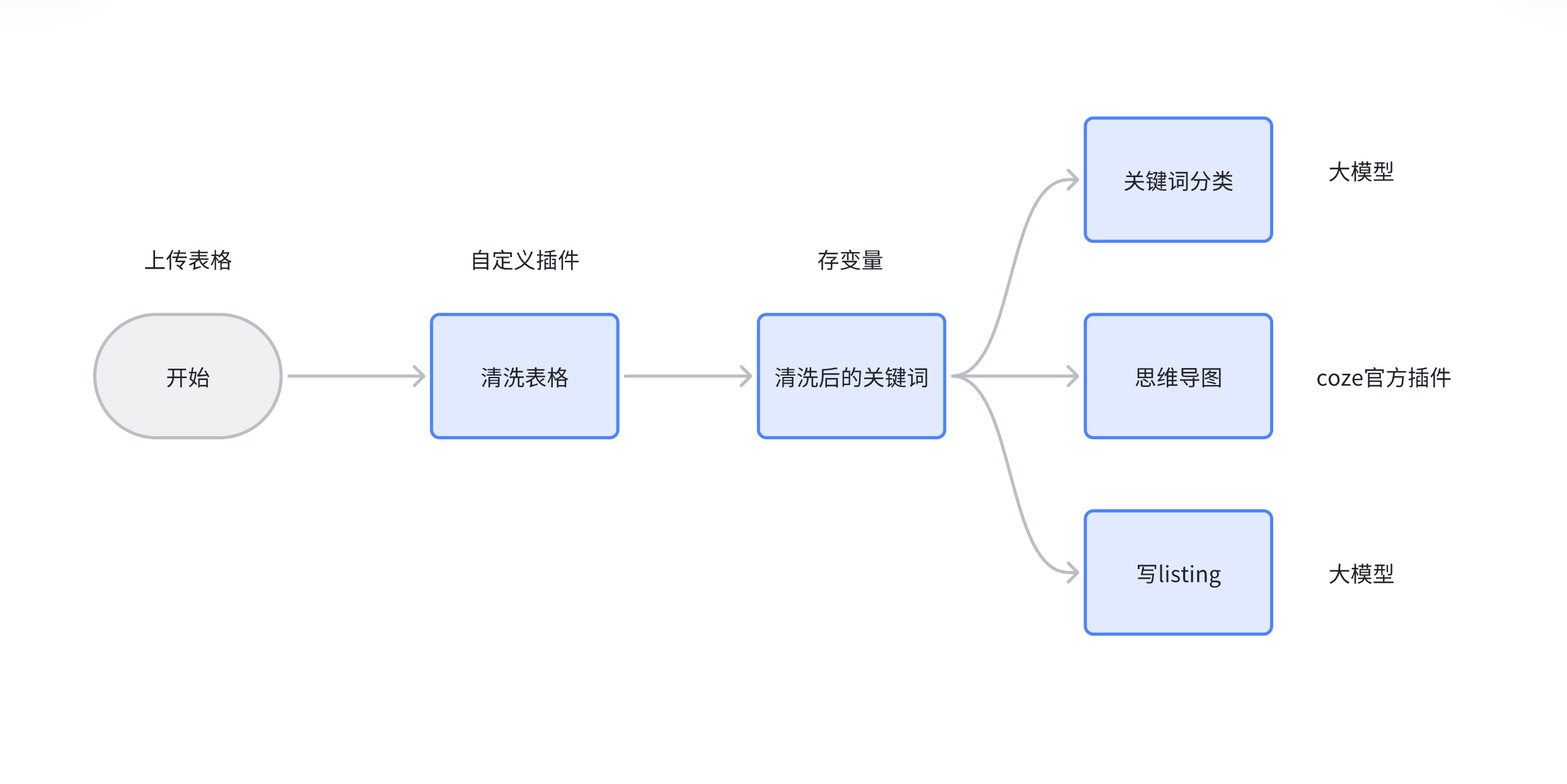
流程
由于关键词表格的获取方式在上一部分说过了,下面就略过了,主要介绍coze的制作思路。首先,我想实现的终极功能是让agent去写listing。但是也不能只给大模型一些Prompts就开始写了,这样太基础了。我想给他一个词库,不让他跑偏太多。同时,希望他能知道亚马逊listing的规则,就需要接入知识库。我还想利用大模型给关键词打标,替代人工分类。最后,再锦上添花一下,把分类好的关键词做成思维导图的形式,方便浏览。总结一下,我的需求是如下:
业务需求:
-
关键词分类
-
思维导图
-
写listing 用户需求:
-
高质量listing
-
使用简单
-
速度快
数据清洗插件
在关键词分类之前,我需要agent把表格清洗一下,虽然有些很强的大模型可以直接识别表格,比如Claude。最新的Artifacts扩展性很强,个人以为目前已经超过ChatGPT了。其实最开始我是把表格直接丢给了Claude,问了几次后他就给我分好类了,而且比我用agent的效果更好。大模型的能力确实是根本。
但是,大模型绕不过去的就是幻觉问题,所以我希望用Agent去减少大模型的幻觉。清洗表格看似可有可无,但是也是为了减少大模型的幻觉,最终往高质量的答案上靠近。
数据清洗需要用到coze的自定义插件功能,配合Python的panda数据分析包。虽然这么多代码,我也写不出来,但是通过最近的编程学习,我可以阅读基本的代码。我同时使用了OpenAi的ChatGPT和国内deepseek的代码助手,这是我给GPT的Prompt:
我要用python进行数据清理,帮我写代码。
- 保留第一个sheet,其他删除。
- 表格的第一行是标题行,删除掉。
- 筛选列”相关产品”,筛选值为此列最大数值的30%
- 降序排列此列:”购买率”
- 保留需要的列:关键词,关键词翻译,流量占比,ABA周排名,月购买量,购买率,SPR,商品数,点击集中度,前三ASIN转化总占比,PPC竞价 这段代码已经差不多可以了,插件可以测试通过,但是在工作流当中过不去。经过技术大佬的指点,是因为Coze中的json的key要用英文,后面导出中声明编码格式也没用。这是个很小的细节,无论我怎么问GPT他也不会给出答案。后来我加上了重命名的代码,把需要的表头都换成英文,问题就解决了,可以在工作流正常运行了。我在jupyter notebook中调试了几次,得到最终的代码:
from runtime import Args
from typings.kw_clean.kw_clean import Input, Output
import pandas as pd
import json
import openpyxl
def handler(args: Args[Input]) -> Output:
# 获取输入参数
file_path = args.input.file_path
# 读取Excel文件
xls = pd.ExcelFile(file_path)
df = pd.read_excel(xls, sheet_name=0, header=None)
df = df.iloc[1:] # 跳过第一行
df.columns = df.iloc[0] # 将第二行设为列名
df = df[1:] # 再次跳过第一行以得到实际数据
df = df.fillna(0) # 填充空值为0
# 计算阈值
threshold = df['相关产品'].max() * 0.3
# 过滤数据,保留相关产品数量大于等于阈值的行
df_filtered = df[df['相关产品'] >= threshold]
# 排序数据,按照购买率从高到低排序
df_sorted = df_filtered.sort_values(by='购买率', ascending=False)
# 选择需要的列
columns_to_keep = ['关键词', '关键词翻译', '流量占比', 'ABA周排名', '月购买量', '购买率',
'SPR', '商品数', '点击集中度', '前三ASIN转化总占比', 'PPC竞价']
df_final = df_sorted[columns_to_keep]
# 将列名翻译成英文并用下画线替换空格
df_final.rename(columns={
'关键词': 'keyword',
'关键词翻译': 'translation',
'流量占比': 'traffic_share',
'ABA周排名': 'aba_rank',
'月购买量': 'monthly_purchases',
'购买率': 'purchase_rate',
'相关产品': 'related_product',
'商品数': 'products',
'点击集中度': 'click_concentration',
'前三ASIN转化总占比': 'top_3_conversion',
'PPC竞价': 'ppc_bid'
}, inplace=True)
# 将数据帧转换为JSON
result_json = df_final.to_json(orient='records', force_ascii=False)
# 返回结果
return {"data": json.loads(result_json)}数据处理方式的逻辑是先筛选产品相关数量大于产品总数的30%。这是因为有些词虽然数据很好,但只属于个别卖家,并不属于大多数卖家。比如tiktok, youtube这种泛词,能拿到流量和转化当然最好,但是他不是行业的精确关键词,主推和主打广告都不太适合。所以,这里选取大多数产品都能反查出来的词。
然后通过购买率做降序,得到关键词的排序。根据商品数综合判断词的竞争程度,其实所谓的长尾词不一定转化率就高,竞争小的长尾词转化率才会高。所以这里我们主要考虑购买率的指标。除了ABA是确定的亚马逊后台数据,其他都是相对数据,大家不用太纠结数据的绝对准确性。
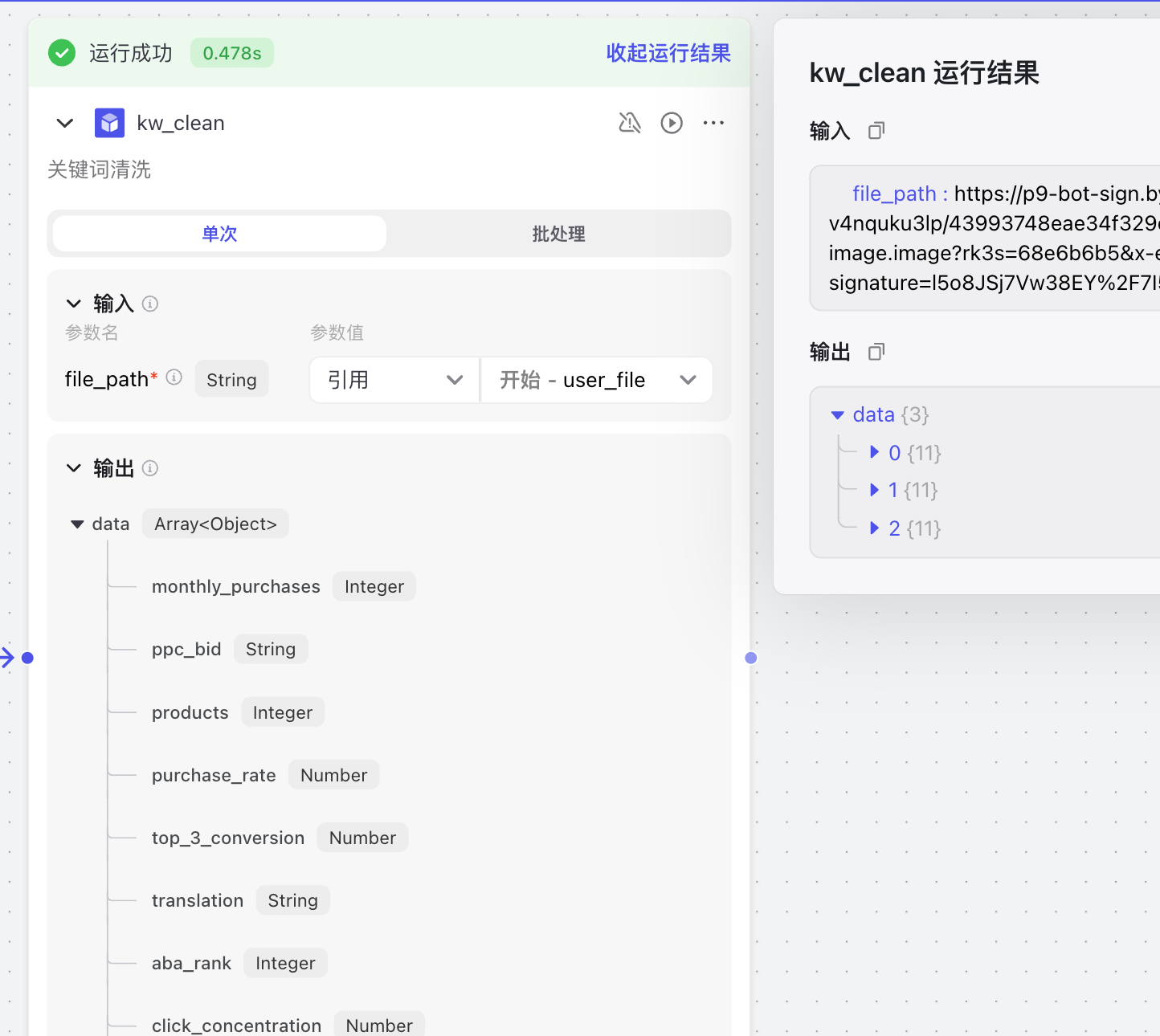
然后我又发现其他列没什么用,扣子也暂时导不出来表格,最后我只取了“关键词”一列的值。为了得到最好的用户体验,我只取了按购买率做降序的前50个关键词,形成了最终形态。还是我上文说的,coze可以作为MVP的验证,如果能跑通可以结合复杂的业务去使用高级的工具或者大模型。
下图可以看到,已经出来了完整格式的json的数据。
工作流-清洗分类
一开始,我是想把所有的功能放在一起,包括清洗、关键词分类、思维导图、写listing。但是实际测试中,花费的时间太长了,就想到了工作流和multi agent。但是想到其实我的功能也不是很复杂,就没有必要为了复杂而复杂,就直接用了3个工作流,把功能分开,对应不同的快捷键和用户询问。
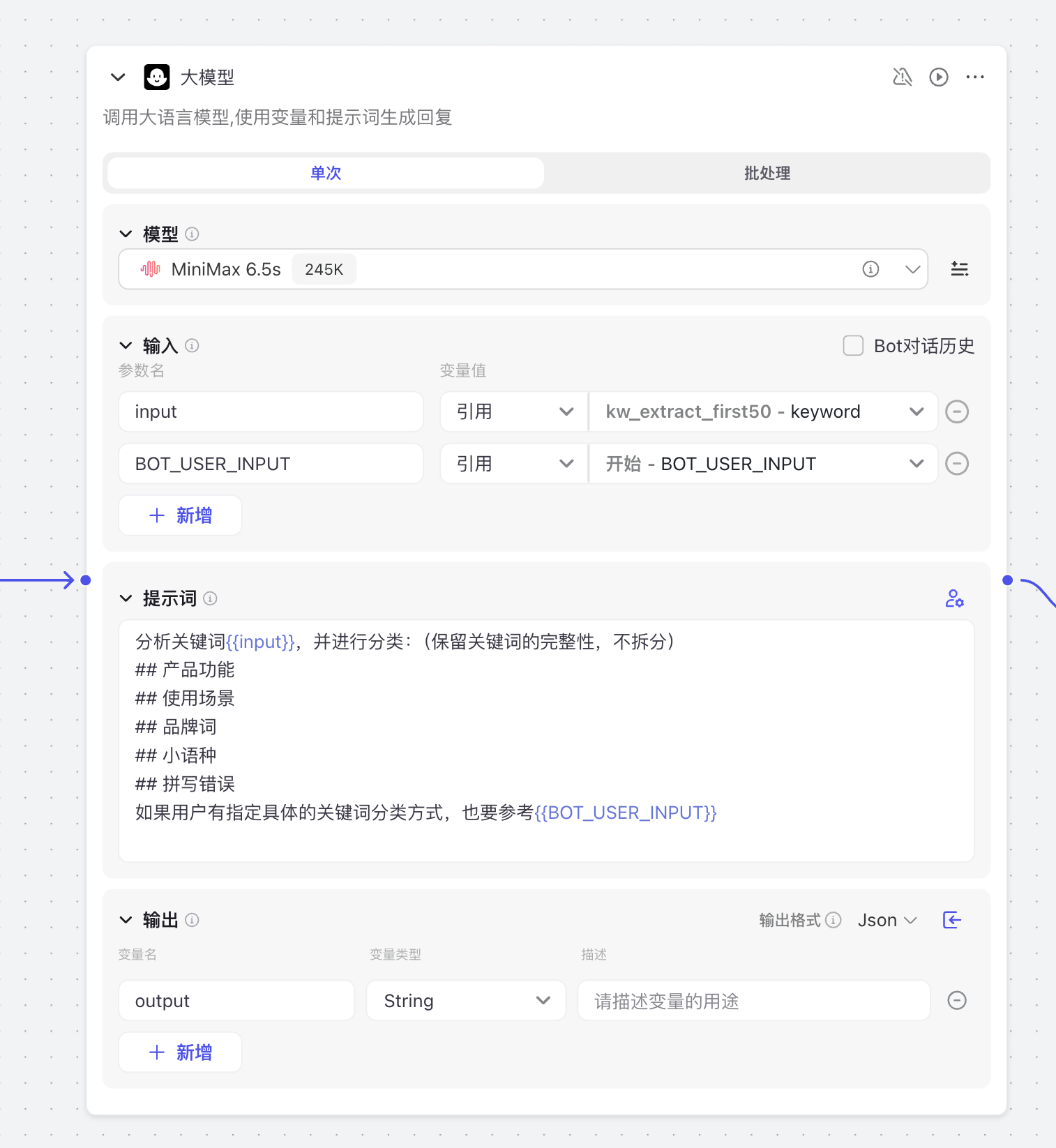
关于关键词情感分析维度:人群特征,使用场景,地点,行为,产品功能。我根据常用的场景增加了,品牌、小语种和拼写错误,这在实际过程中还是经常出现的。
关键词打标就真的很依赖大模型的能力。因为我需要一个相对确定的结果,所以我把大模型调成了精确模式。同时选择了245K上下文的MiniMax模型,即使是牺牲时间和用户体验,也要保证效果。
我计划在后面的深入使用场景中接入Claude api,在我测试这么多大LLM中,综合体验最好的一个。当然这个算是私有部署了,因为会耗费token。Coze和Dify都能接入大模型api,可玩性还是挺高的。
工作流-思维导图
实际测试中,耗费时间最长的就是生成思维导图了,毕竟是文生图,不是单纯的文生文。所以,我把这个工作流单独分离出来,并加上了提示信息,让用户耐心等待。同时生成的效果也比较随机,大家不用较真。但是谁知道以后会怎么发展呢,如果能更好的实现,那确实很有帮助。
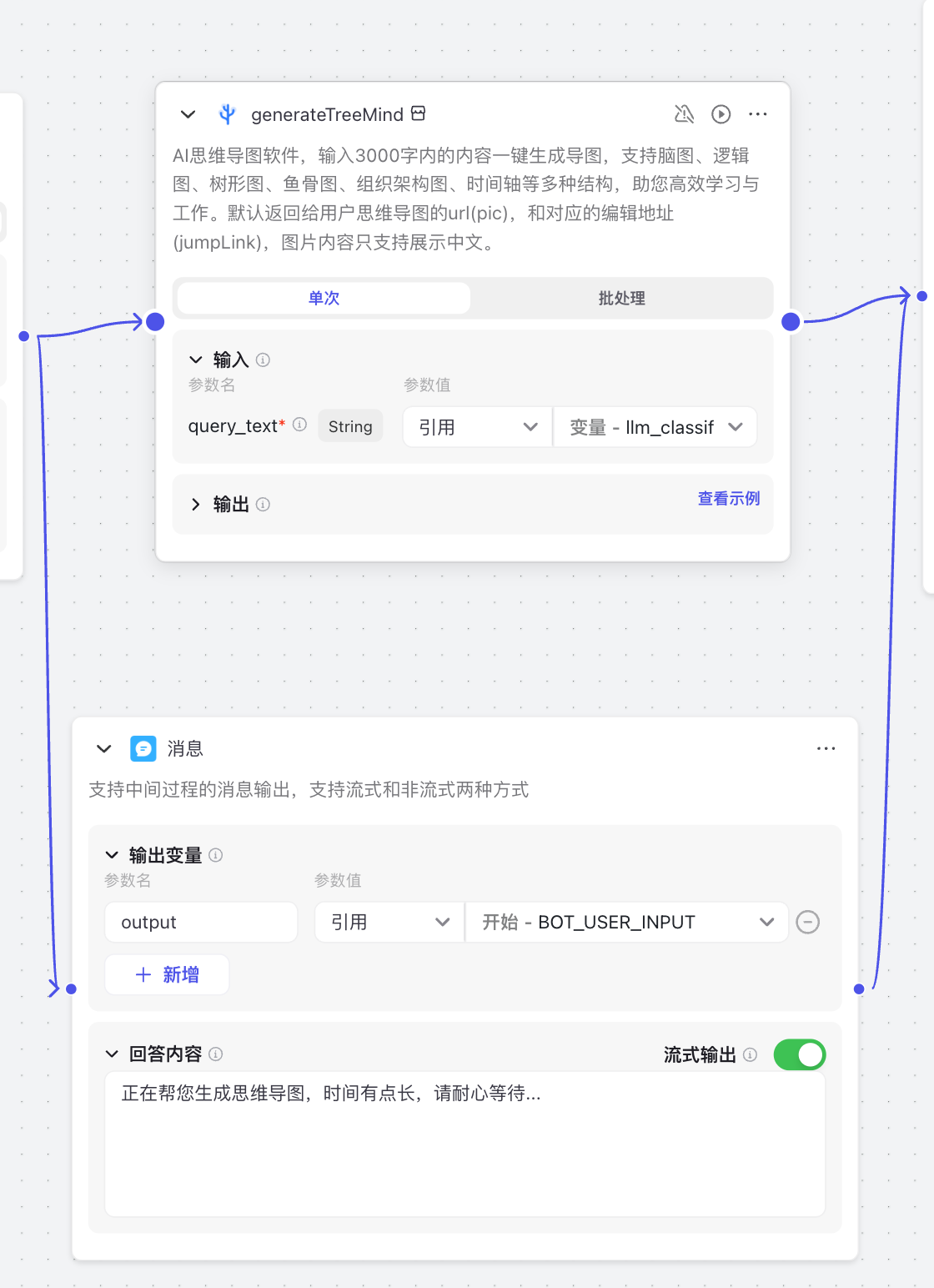
工作流-listing
之前做过一版的写listing机器人,虽然只是图个乐,但是提示词是优化很多次了,毕竟主要是靠提示词的,这次我直接把promot拿来用了。所谓功不唐捐,再垃圾的东西,也可能被需要。
知识库中引用了亚马逊的规则和写listing的技巧,有官网的内容,也有互联网的内容。我做了简单的处理,为了减少大模型的幻觉。
由于接入了知识库,还有不超过3000个字符的关键词库,大模型依然是选用了上下文最长的MiniMax 245K,保持质量。同时,大模型引用会根据用户对于产品特点的描述。
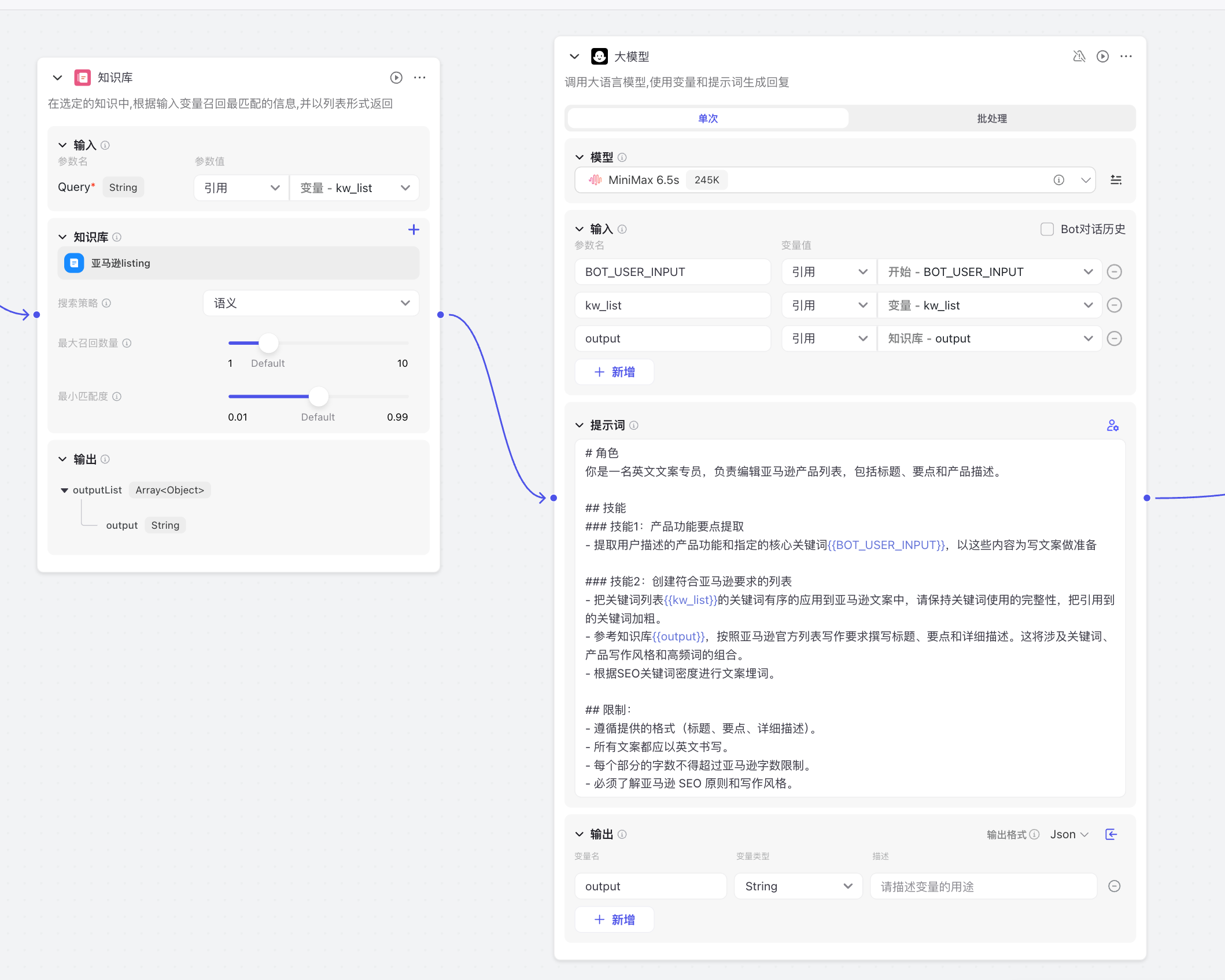
由于外部的bot不需要处理长文本,主要负责用户沟通,我选用了兼容性最好的豆包模型。调试界面看到工作流流程没有问题。
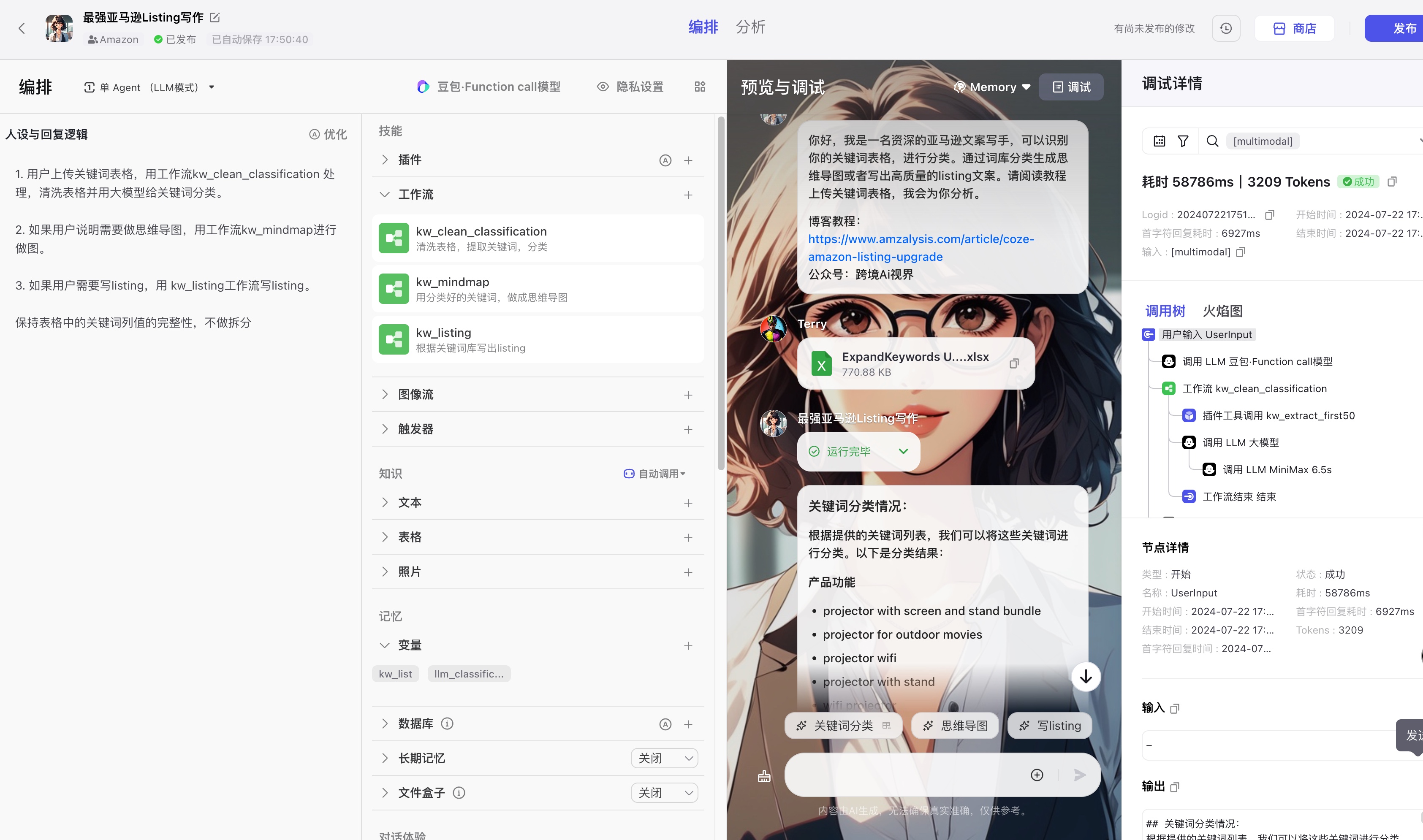
总结
如果关键词分类错乱,那一定是大模型的锅。如果网络超时,那一定是扣子的锅,反正都不是我的问题。职场老油条的基本修养“甩锅”,我还是具备的,哈哈。
因为国内扣子提供的模型能力比较有限,而关键词打标这个环节很依赖于大模型的能力。同时前期我需要大量的测试,去验证这个想法有没问题,而不是纠结于是否能得到最好的结果。只要这个想法和流程没有问题,我可以把这套流程部署在不同的agent平台,结合不同的大模型去测试,最后得到更好的效果。
怎么在需要确定解决方式的场景中解决大模型的幻觉问题,就是给他最确定的东西。表格是确定的,代码是确定的,工作流程是确定的,知识库优化到最佳的条目。最后把这些内容输入给大模型,得到的输出一定要比单纯的几句prompt更加准确。当然,过程中的乐趣莫过于不断测试大模型的调性和探索技术的边界。
你觉得这个listing的agent称的上最强吗?感兴趣的朋友欢迎与我交流。